
Straight to the Point: Fast-forwarding Videos via Reinforcement Learning Using Textual Data
2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Abstract
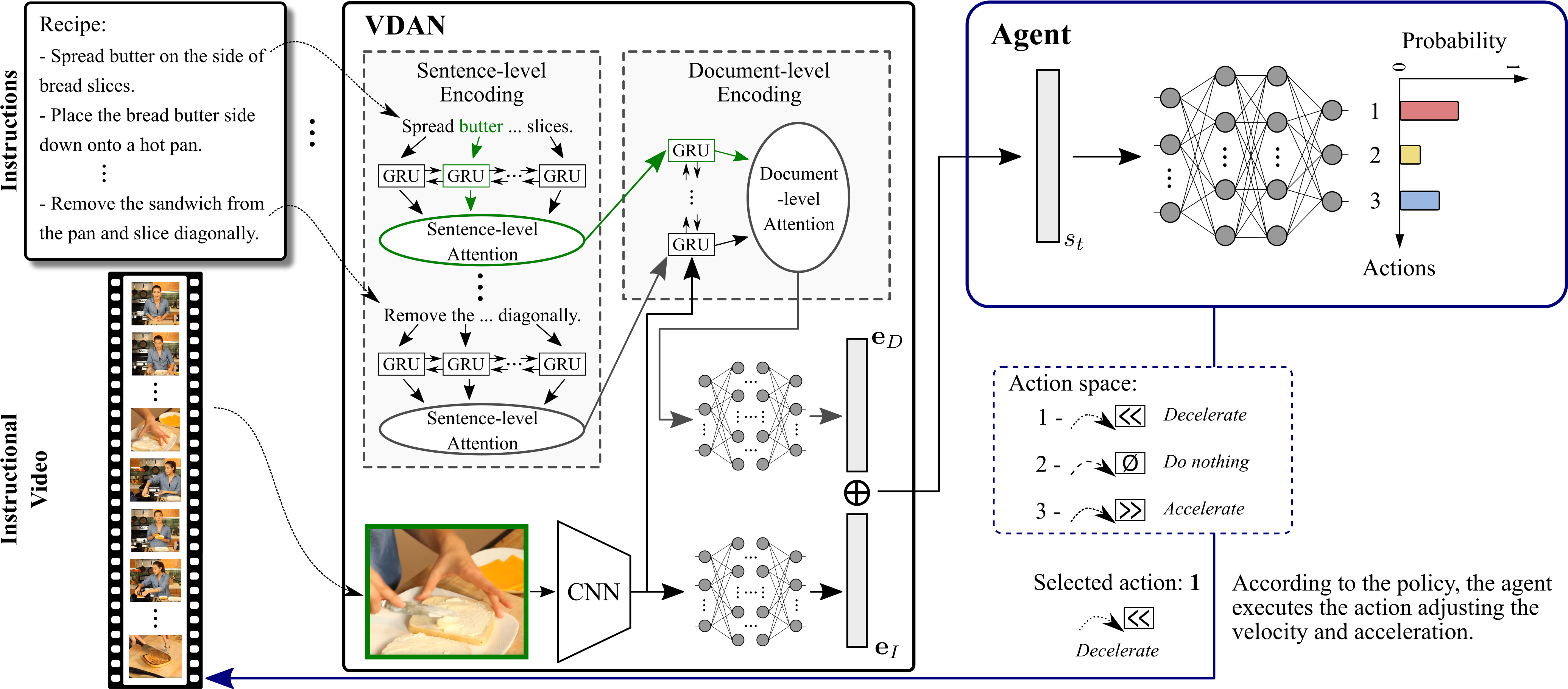
The rapid increase in the amount of published visual data and the limited time of users bring the demand for processing untrimmed videos to produce shorter versions that convey the same information. Despite the remarkable progress that has been made by summarization methods, most of them can only select a few frames or skims, which creates visual gaps and breaks the video context. In this paper, we present a novel methodology based on a reinforcement learning formulation to accelerate instructional videos. Our approach can adaptively select frames that are not relevant to convey the information without creating gaps in the final video. Our agent is textually and visually oriented to select which frames to remove to shrink the input video. Additionally, we propose a novel network, called Visually-guided Document Attention Network (VDAN), able to generate a highly discriminative embedding space to represent both textual and visual data. Our experiments show that our method achieves the best performance in terms of F1 Score and coverage at the video segment level.
|
Source code (NEW!) |
Methodology and Visual Results |
Citation
@InProceedings{Ramos2020cvpr,
author={W. {Ramos} and M. {Silva} and E. {Araujo} and L. S. {Marcolino} and E. {Nascimento}},
booktitle={2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
title={Straight to the Point: Fast-Forwarding Videos via Reinforcement Learning Using Textual Data},
year={2020},
volume={},
number={},
pages={10928-10937},
}
author={W. {Ramos} and M. {Silva} and E. {Araujo} and L. S. {Marcolino} and E. {Nascimento}},
booktitle={2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
title={Straight to the Point: Fast-Forwarding Videos via Reinforcement Learning Using Textual Data},
year={2020},
volume={},
number={},
pages={10928-10937},
}
Authors

Washington Luis de Souza Ramos
PhD Candidate
Michel Melo da Silva
Researcher
Edson Roteia Araujo Junior
MSc Student
Leandro Soriano Marcolino
Lecturer LU/UK