
Learning to Dance: A graph convolutional adversarial network to generate realistic dance motions from audio
Computers & Graphics
Abstract
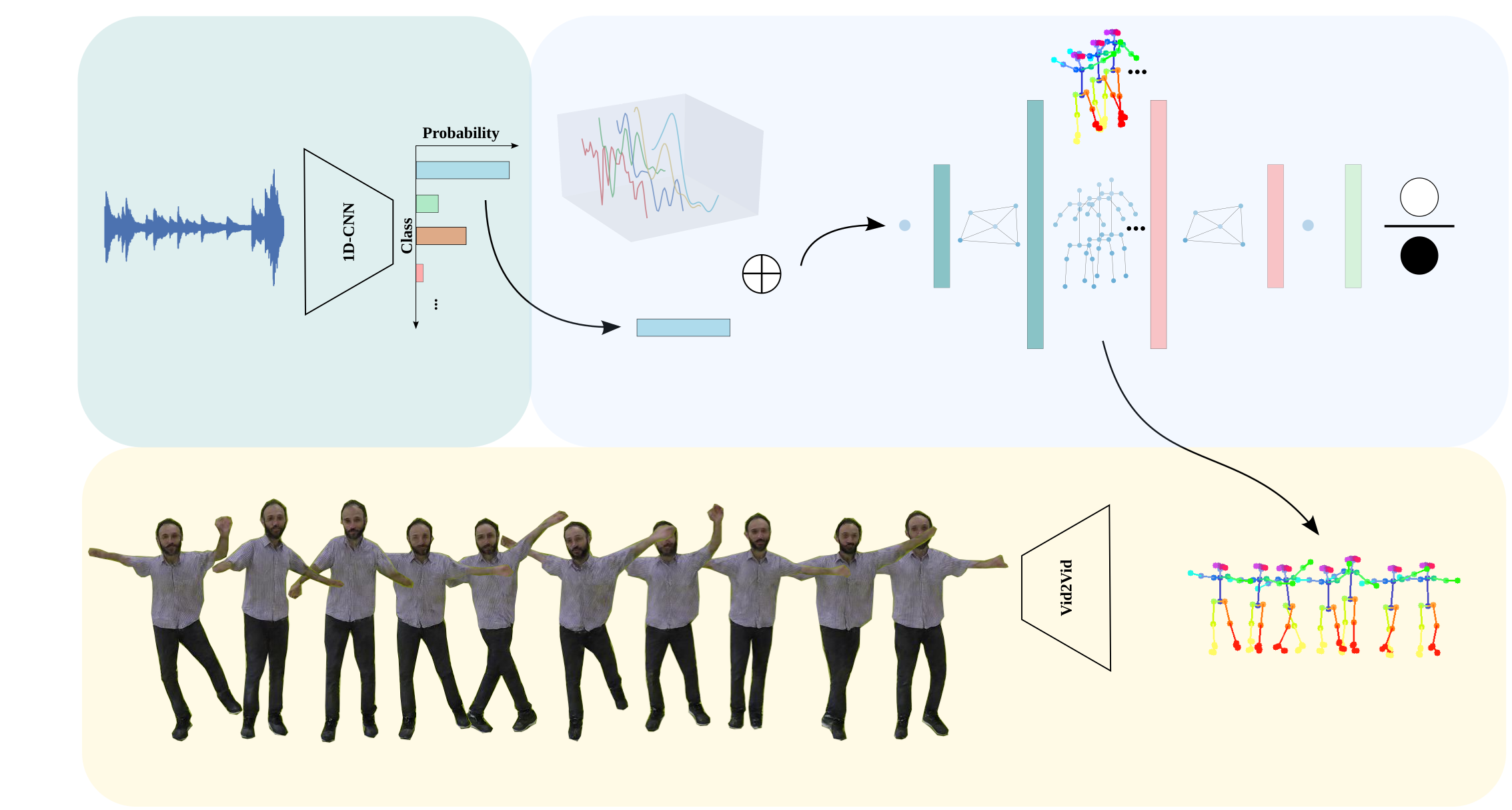
Synthesizing human motion through learning techniques is becoming an increasingly popular approach to alleviating the requirement of new data capture to produce animations. Learning to move naturally from audio, and in particular to dance, is one of the more complex motions humans often perform effortlessly. Each dance movement is unique, yet such movements maintain the core characteristics of the dance style. Most approaches addressing this problem with classical convolutional and recursive neural models undergo training and variability issues due to the non-Euclidean geometry of the motion manifold structure. In this paper, we design a novel method based on graph convolutional networks to tackle the problem of automatic dance generation from audio information. Our method uses an adversarial learning scheme conditioned on the input music audios to create natural motions preserving the key movements of different music styles. We evaluate our method with three quantitative metrics of generative methods and a user study. The results suggest that the proposed GCN model outperforms the state-of-the-art dance generation method conditioned on music in different experiments. Moreover, our graph-convolutional approach is simpler, easier to be trained, and capable of generating more realistic motion styles regarding qualitative and different quantitative metrics. It also presented a visual movement perceptual quality comparable to real motion data.
Citation
@article{ferreira2021cag,
author = “João P. Ferreira and Thiago M. Coutinho and Thiago L. Gomes and José F. Neto and Rafael Azevedo and Renato Martins and Erickson R. Nascimento”,
title = “Learning to dance: A graph convolutional adversarial network to generate realistic dance motions from audio”,
journal = “Computers & Graphics”,
volume = “94”,
pages = “11 – 21”,
year = “2021”,
issn = “0097-8493”,
doi = “https://doi.org/10.1016/j.cag.2020.09.009”,
}
Methodology and Visual Results
Authors

João Pedro Moreira Ferreira
MSc Student
Thiago Malta Coutinho
MSc Student
Thiago Luange Gomes
Researcher
José Francisco da Silva Neto
PhD Student
Rafael Augusto Vieira de Azevedo
MSc Student
Renato José Martins
Professor at Université de Bourgogne